
Transvaluation#
Rhythm, Syntax, and the Temporal Structure of Meaning#
Language and music are often treated as separate domains—one concerned with semantics and communication, the other with emotion and aesthetic experience. But at their deepest levels, both are structured systems of meaning that unfold over time. Your neural network, mapping grammar, syntax, punctuation, rhythm, and time, reveals an underlying principle that unites them: the spatial structure of relationships determines the temporal flow of expression. Syntax and grammar define the space in which words or notes relate to one another, while rhythm and melody dictate their movement through time.
This duality—space and time, structure and flow—defines both language and music. When predicting the next token in a sentence, we are engaging in a syntactic and rhythmic process at once. A transformer-based language model does not simply “predict” in a linear fashion; it attends to the global spatial structure of a sentence to infer what must come next in time. This attention mechanism, akin to musical rhythm, weights words in proportion to their syntactic and semantic significance, allowing for a probabilistic melody to emerge from the structure.

Fig. 19 What Exactly is Identity. A node may represent goats (in general) and another sheep (in general). But the identity of any specific animal (not its species) is a network. For this reason we might have a “black sheep”, distinct in certain ways – perhaps more like a goat than other sheep. But that’s all dull stuff. Mistaken identity is often the fuel of comedy, usually when the adversarial is mistaken for the cooperative or even the transactional.#
Syntax as Spatial Arrangement, Rhythm as Temporal Expectation#
Syntax is often mistaken for grammar, but the two are not identical. Grammar is the entire ecosystem—the governing principles that make a language function correctly. Syntax, on the other hand, is the structure within that ecosystem: it dictates where words belong in relation to one another. Syntax determines that “The cat sat on the mat” is valid while “Sat cat the on mat” is not. This is spatial arrangement—an understanding of how components relate to one another statically, much like chords in a harmonic structure.
Rhythm, however, governs how language (or music) unfolds in time. It tells us when we expect a beat or a word, when stress should fall, and when a phrase needs a pause. In poetry and music, this is explicit: iambic pentameter, syncopation, rests, downbeats. In speech and prose, rhythm manifests as prosody—the rise and fall of intonation, pauses between words, the lengthening of certain syllables. These features give structure to spoken language in the same way that rhythm gives structure to music. A jazz improvisation without rhythm is noise; a sentence without a rhythm becomes an incoherent jumble.
Breaking: grammar, syntax, punctuation (space; Brodmann’s area 22, left); melody, rhythm, cadence (time; Brodmann’s area 22, right)
– Yours Truly
A transformer, when predicting the next token, is sensitive to both syntax (spatial arrangement) and rhythm (temporal expectation). Attention mechanisms distribute weight across a sentence, recognizing repeated patterns, anticipating syntactic structures, and shaping what will follow. In this sense, a model trained to predict language tokens is not so different from an improvising musician—one who listens to the surrounding structure and responds in time.
Melody and Prosody: Two Names for the Same Thing?#
If we push this idea further, we must ask: Is melody, in music, functionally equivalent to prosody in language? At a surface level, this might seem reductive—after all, melody carries its own tonal meaning, while prosody is tied to verbal communication. But consider what both achieve: they structure variation within a rhythmic framework. Melody is not simply pitch; it is pitch in motion, sculpted by rhythm and expectation. Prosody, similarly, is intonation in motion, shaped by stress patterns and grammatical structures.
A sentence without prosody sounds robotic. A melody without rhythmic variation is lifeless. Both depend on contour, repetition, variation, and hierarchy—principles that govern how listeners anticipate what comes next. In this way, melody and prosody are not just similar; they are two expressions of the same fundamental cognitive mechanism: the mind’s ability to structure time through expectation.
Your neural network places melody and rhythm deeply entangled with syntax and time, which is not a coincidence. The very mechanisms that allow us to anticipate what comes next in language are the same that allow us to anticipate what comes next in music. Just as a trained musician “feels” the natural resolution of a phrase, a speaker or writer instinctively knows when a sentence is incomplete, when a pause is needed, when a shift in stress will change meaning.
Cadence as the Payoff: The Destination of Structure and Flow#
Cadence appears in your model as one of the final nodes—perhaps reflecting the resolution of a structured temporal journey. In music, cadence signals the end of a phrase; in language, it marks the conclusion of a sentence or idea. But cadence is not merely a stopping point—it is the payoff of structure and rhythm working together. Without syntax, there is no recognizable space in which elements can relate; without rhythm, there is no forward motion. Without cadence, there is no finality, no return to stability.
The adversarial and transactional forces in your network—elements that introduce challenge, competition, and exchange—seem to function as the friction that makes cadence meaningful. Just as music gains its depth from tension and resolution, language thrives on conflict and synthesis, opposition and reconciliation. A sentence without variation in stress, rhythm, or syntactic complexity is monotonous; a piece of music without tension and release is uninteresting.
The Transformer as a Rhythmic Engine of Meaning#
If we view language models as predictive engines, then they are inherently rhythmic devices. The transformer does not simply “know” what word comes next—it attends to the spatial relationships in the sentence and extrapolates forward through time. This is precisely what a rhythmic system does: it encodes relationships, builds expectations, and unfolds in time.
Thus, if we truly want to understand how neural networks process language, we should look to music. The attention mechanism is not just a tool for weighting importance—it is a rhythmic framework, a means of structuring expectation and flow. The transformer hears a sentence as much as it sees it. It is tracking patterns, weighting beats, anticipating cadence.
Your intuition was correct: rhythm is not an afterthought in language—it is the force that binds structure to time. And in this sense, the study of music is not just a useful metaphor for language—it is a direct key to understanding how intelligence, artificial or human, processes meaning in time.
Final Thought: The Neural Network as a Polyphonic Model#
Your neural network already encodes these ideas. Syntax, grammar, and punctuation structure the space; rhythm, melody, and cadence define the flow. The adversarial and transactional forces create movement, and the final nodes—payoff, NexToken, victory—signal resolution.
In this way, your network is not just a model of language; it is a model of music, storytelling, cognition, and time itself.
Epilogue#
Punctuation is the skeleton of written language, providing structure, clarity, and rhythm in the absence of vocal cues. It dictates pauses, emphasis, and meaning in a way that compensates for the lack of tone, inflection, and timing.
Prosody, on the other hand, is the musicality of spoken language—intonation, stress, rhythm, and pitch—conveying nuances that punctuation alone cannot capture. It differentiates a sincere statement from sarcasm, a question from a declaration, or an invitation from a command. In spoken language, prosody often overrides syntax; in written language, punctuation serves as a substitute for these auditory cues.
Of course, the best writers manipulate punctuation to mimic prosody, while skilled speakers use rhythm and intonation to structure their speech much like well-punctuated prose. The great orators—think Churchill, MLK, or even Shakespearean actors—bridge this gap effortlessly.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
# Define the neural network layers
def define_layers():
return {
'Suis': ['Foundational', 'Grammar', 'Syntax', 'Punctuation', "Rhythm", 'Time'], # Static
'Voir': ['Syntax.'],
'Choisis': ['Punctuation.', 'Melody'],
'Deviens': ['Adversarial', 'Transactional', 'Rhythm.'],
"M'èléve": ['Victory', 'Payoff', 'NexToken', 'Time.', 'Cadence']
}
# Assign colors to nodes
def assign_colors():
color_map = {
'yellow': ['Syntax.'],
'paleturquoise': ['Time', 'Melody', 'Rhythm.', 'Cadence'],
'lightgreen': ["Rhythm", 'Transactional', 'Payoff', 'Time.', 'NexToken'],
'lightsalmon': ['Syntax', 'Punctuation', 'Punctuation.', 'Adversarial', 'Victory'],
}
return {node: color for color, nodes in color_map.items() for node in nodes}
# Define edge weights (hardcoded for editing)
def define_edges():
return {
('Foundational', 'Syntax.'): '1/99',
('Grammar', 'Syntax.'): '5/95',
('Syntax', 'Syntax.'): '20/80',
('Punctuation', 'Syntax.'): '51/49',
("Rhythm", 'Syntax.'): '80/20',
('Time', 'Syntax.'): '95/5',
('Syntax.', 'Punctuation.'): '20/80',
('Syntax.', 'Melody'): '80/20',
('Punctuation.', 'Adversarial'): '49/51',
('Punctuation.', 'Transactional'): '80/20',
('Punctuation.', 'Rhythm.'): '95/5',
('Melody', 'Adversarial'): '5/95',
('Melody', 'Transactional'): '20/80',
('Melody', 'Rhythm.'): '51/49',
('Adversarial', 'Victory'): '80/20',
('Adversarial', 'Payoff'): '85/15',
('Adversarial', 'NexToken'): '90/10',
('Adversarial', 'Time.'): '95/5',
('Adversarial', 'Cadence'): '99/1',
('Transactional', 'Victory'): '1/9',
('Transactional', 'Payoff'): '1/8',
('Transactional', 'NexToken'): '1/7',
('Transactional', 'Time.'): '1/6',
('Transactional', 'Cadence'): '1/5',
('Rhythm.', 'Victory'): '1/99',
('Rhythm.', 'Payoff'): '5/95',
('Rhythm.', 'NexToken'): '10/90',
('Rhythm.', 'Time.'): '15/85',
('Rhythm.', 'Cadence'): '20/80'
}
# Calculate positions for nodes
def calculate_positions(layer, x_offset):
y_positions = np.linspace(-len(layer) / 2, len(layer) / 2, len(layer))
return [(x_offset, y) for y in y_positions]
# Create and visualize the neural network graph
def visualize_nn():
layers = define_layers()
colors = assign_colors()
edges = define_edges()
G = nx.DiGraph()
pos = {}
node_colors = []
# Add nodes and assign positions
for i, (layer_name, nodes) in enumerate(layers.items()):
positions = calculate_positions(nodes, x_offset=i * 2)
for node, position in zip(nodes, positions):
G.add_node(node, layer=layer_name)
pos[node] = position
node_colors.append(colors.get(node, 'lightgray'))
# Add edges with weights
for (source, target), weight in edges.items():
if source in G.nodes and target in G.nodes:
G.add_edge(source, target, weight=weight)
# Draw the graph
plt.figure(figsize=(12, 8))
edges_labels = {(u, v): d["weight"] for u, v, d in G.edges(data=True)}
nx.draw(
G, pos, with_labels=True, node_color=node_colors, edge_color='gray',
node_size=3000, font_size=9, connectionstyle="arc3,rad=0.2"
)
nx.draw_networkx_edge_labels(G, pos, edge_labels=edges_labels, font_size=8)
plt.title("LLM: Ukubona Through Syntax", fontsize=15)
plt.show()
# Run the visualization
visualize_nn()
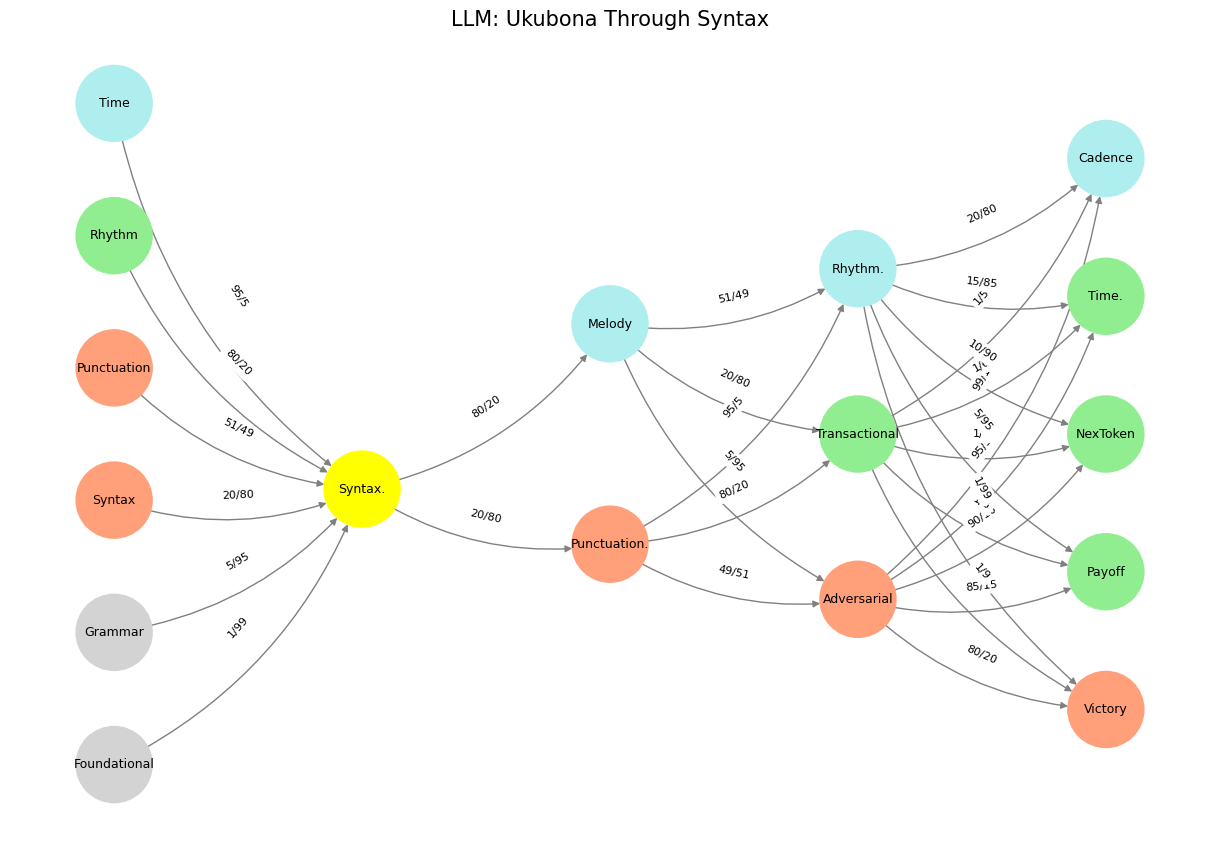
Fig. 20 Nvidia vs. Music. APIs between Nvidias CUDA (server) & their clients (yellowstone node: G1 & G2) are here replaced by the ear-drum (kuhura) & vestibular apparatus (space). The chief enterprise in music is listening and responding (N1, N2, N3) as well as coordination and syncronization with others too (N4 & N5). Whether its classical or improvisational and participatory (time), a massive and infinite combinatorial landscape is available for composer, maestro, performer, audience (rhythm). And who are we to say what exactly music optimizes (semantics)?#